




When it comes to computer vision, a frequently asked question is: what is the difference between image classification, object detection, and image segmentation?
One of the most widely recognized fields of artificial intelligence is computer vision. This field involves developing software and techniques that can recognize and classify images. Humans are capable of easily identifying and detecting objects. We know this because our visual system is very accurate and fast. However, in a situation where we have to find a ring from a table consisting of various materials, we might not be able to perform this task very quickly. Getting the right key can take a long time. With the help of a computer algorithm, we can easily find a ring without wasting any time. With the availability of huge amounts of data and algorithms, we can train the system to identify and classify various objects with high accuracy.
Image classification
Image classification is a machine learning technique that involves training models to identify which classes (objects) are present in an image or video, i.e., categorizing and labeling groups of pixels or vectors in an image so that they can be organized according to specific rules. Due to the vast amount of data collected from sensors and cameras, image classification is one of the most critical components of this digital image analysis. This process is carried out using deep learning models, which are capable of performing various tasks with accuracy that is beyond human-level. Image classification systems are commonly used in various areas, such as medical imaging, traffic control systems, object identification from satellite images, and machine vision.
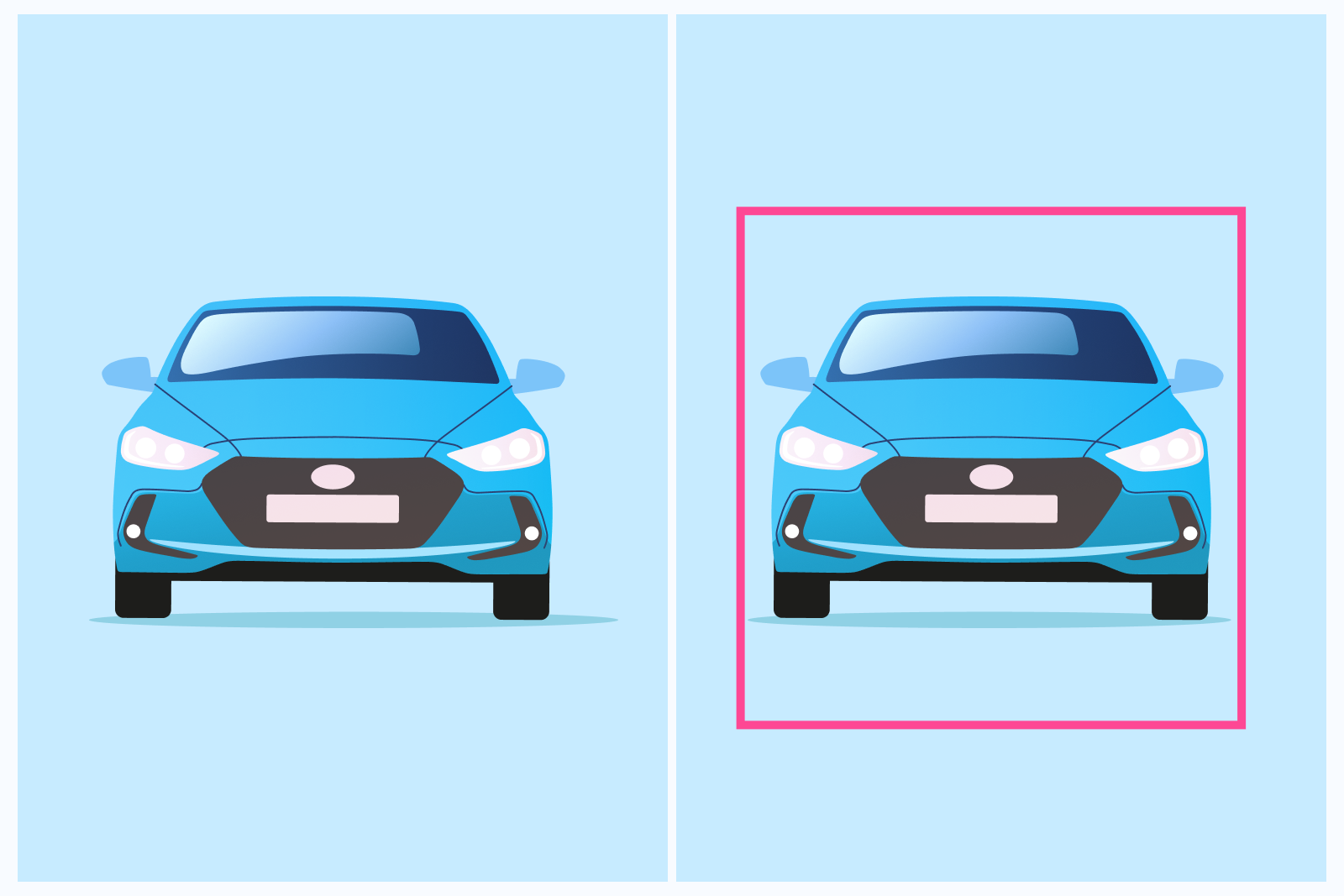
For instance, in the image given below, the image of a car can be classified as a class label “car” with some probability.

This technique is useful at the yes-no level of deciding whether an image contains an object or not. A separate task from the classification is localization, or determining the position of the classified objects in the image or video. For instance, in the above image, you not only classify the entire image as one of the class, “car”, but also find the location of the object within the image with a bounding box.
Object Detection
Object detection is a significant task in computer vision used to detect instances of visual objects from a specific class, for example, humans, animals, cars, or buildings, in digital images. The objective of object detection is to build computational models that offer the most basic information required by computer vision applications, such as “What objects are where?”.
The object detection process combines the two main methods of classification and localization, which are used to determine what objects are in an image or video and where. It takes an input image and produces a set of boxes, which are labeled with a class label. These algorithms are capable of handling various types of classification and localization, as well as dealing with multiple instances. Object detection can be used for various applications, such as facial recognition, vehicle detection systems, people counting, facial recognition, pose detection, text detection, etc.
Consider the below image that has multiple objects in it – such as a woman, man, traffic light, car, etc. Object detection locates the members of each class with bounding boxes.
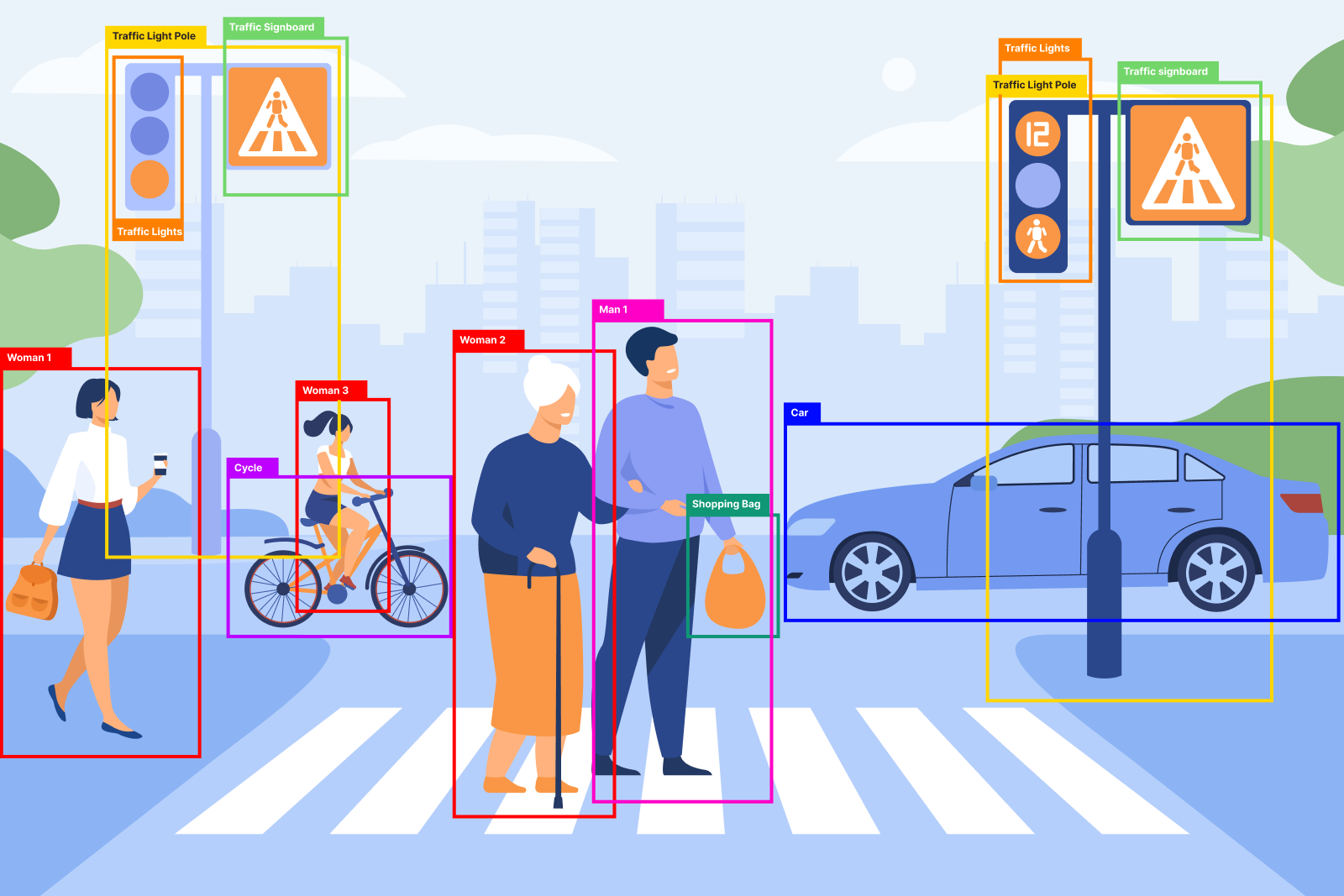
Image Segmentation
Image segmentation is a sub-domain of computer vision and digital image processing which groups similar regions or segments of an image under their respective class labels. It is an extension of object detection in which we mark the presence of an object through pixel-wise masks generated for each object in the image.
Image segmentation partitions an image into semantically meaningful parts or regions at a more granular level. It simplifies image analysis and understanding and is a prerequisite for many high-level computer vision tasks such as object detection and recognition. This method is more precise than bounding box generation because it can help us determine the shape of each object present in the image. This precision is helpful in fields such as medical image processing, robotics, autonomous vehicles, satellite imaging, etc.
Image segmentation can be performed in two broad categories: semantic segmentation and instance segmentation.
- Instance segmentation separates distinct objects from the same class. The image below has multiple objects. With instance segmentation, multiple objects of the same class, let’s say “woman”, would be assigned distinct colors because they are different instances of the class.

- Under semantic segmentation, each pixel belonging to a specific class will be assigned to the same color. For example, any pixel belonging to any woman from the image will be assigned to the class “woman”.

We believe our article has made it very clear to understand what image classification and localization, object detection, and image segmentation mean with the help of simple examples. If you are facing object detection or image segmentation or any computer vision challenge, we have the right solution for you. DeepLobe is a powerful AutoML platform for businesses and enterprises to deliver computer vision projects by providing pre-trained and customizable AI models faster and at lower costs. For more details and to book a demo to check out how DeepLobe works, contact us.